家庭宽带环境下centos8 nginx 配置ipv6公网访问 最近换了移动的宽带,没有公网ipv4,好像可以开一个公网ip的叠加包。但是本着能省钱就省钱的原则,ipv6本身也比较普及了,正好就来折腾一下。 移动宽带默认就是支持ipv6的,而且移动光猫的配置也没有防火墙限制(可能跟光猫的版本有关,可以搜索相关教程确认是否需要修改配置,我的是 h3-2slite),机器离光猫比较近就直接用网线连的光猫的路由,没有使用接出来的无线路由器上的接口,要是接的外接出来的无线路由器,需要再路由器上开启ipv6的支持,且要注意防火墙之类的问题。 * 验证是否支持ipv6,访问网址:https://www.test-ipv6.com/index.html.zh_CN * windows、mac查看本机的ipv6地址:可访问 https://ipw.cn/ipv6/ 的 IPv6 地址查询 * linux查看: ip addr | grep inet6 结果中带有 scope global 的 我这里是linux系统,centos8,使用nginx对外提供服务,nginx最新的版本中已经默认支持ipv6了,
java java 实现 oracle 的 des3 加密、解密 java 实现 oracle 的 des3 加密 解密 。 dbms_obfuscation_toolkit.des3encrypt、dbms_obfuscation_toolkit.des3decrypt
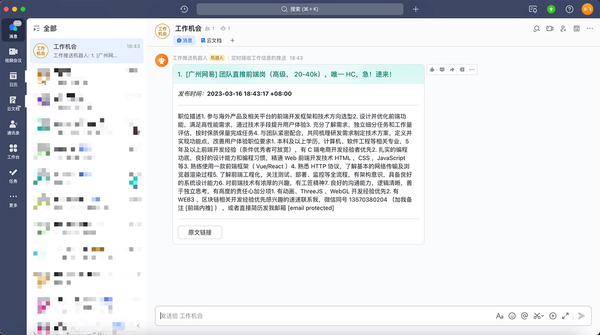
飞书推送 定时抓取招聘信息推送到飞书机器人-v1.2.0-支持电鸭社区 GitHub - lyf-coder/job-opportunity-reminder: 爬取招聘网站上的招聘信息,然后推送到飞书等通讯工具爬取招聘网站上的招聘信息,然后推送到飞书等通讯工具. Contribute to lyf-coder/job-opportunity-reminder development by creating an account on GitHub.GitHublyf-coder 在 v1.1.0 版本上开发,支持抓取 电鸭社区-招聘 数据推送到飞书机器人 * 抓取数据地址: https://eleduck.com/categories/5?sort=new * 通过观察网络请求,发现数据也是后端渲染到页面中,所以需要从页面中提取,比较有趣的是在观察页面的过程中,发现页面上是存在结构化的 json 格式的数据,如图所示: 通过 script 标签的 id=__NEXT_DATA__ 可以获取该数据。
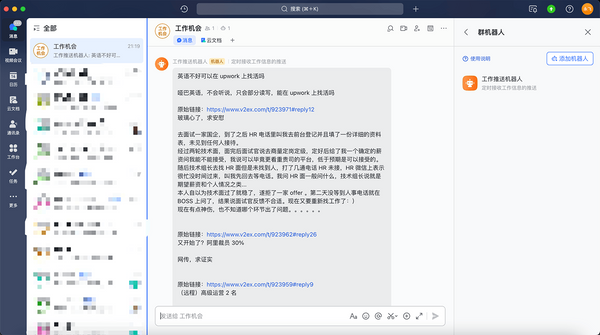
v2ex 访问问题尝试记录 由于 job-opportunity-reminder 项目,发现 Github Action 定时执行的方式不能保证按时可靠的执行(官方限制了高峰时段的执行),所以就想在本地运行的方式,但是 v2ex 的网络问题比较头疼,要么使用代理-这个已实现,但是要是没有代理能不能直接访问呢? * 第一次尝试: 直接解析 v2ex 的 ip (国内的墙会导致访问国内 dns 的到错误的 ip 需要通过别的方式获取),通过 ip 直接访问,结果访问被 cloudfare拦截: * 第二次尝试:还以为是浏览器输入 ip 访问导致的,就尝试修改本地 hosts 文件,然后用代码请求,结果本地无法与目标 ip 建立链接,被重置了,感觉到奇怪,这时候本地没有开代理然后通过 谷歌浏览器 输入域名访问,发现对于 v2ex 的网站是可以加载访问的!问题在哪? * 第三次尝试:
飞书推送 定时抓取招聘信息推送到飞书机器人-v1.1.0 在 版本v1.0.0 实现中发现一些问题: * 发送给飞书的招聘列表 20 条,且格式很难抓住重点,阅读十分不友好 * 推送策略不及时、重复的问题,每天定时推送 20 条,难免会有重复的,因为招聘网站更新的职位可能没多少。每天推送一次,及时性就很差 为了解决上面的问题,就有了 v1.1.0 版本: * 每隔 5分钟 执行一次,只推送 之前5分钟内 创建的招聘信息。 * 飞书推送消息的格式改为: 消息卡片 ,且每条信息单独发送一条消息。 实现 * 定时执行策略实际使用 4分钟 执行一次,而推送消息范围是 5分钟 内的, v2ex 的酷工作默认查询排序是按照最后回复时间进行排序的,所以排在前面的是有最新回复内容的,但是对于招聘信息,目前只关注发送的时间节点就行了,所以通过在详细页面获取发布时间,然后对比执行时间与发布时间的差值是否在 5分钟内 ,为了防止执行启动期间的数据丢失,
go 定时抓取招聘信息推送到飞书机器人-v1.0.0 因为有不少网站论坛都提供一些招聘信息,包括兼职、全职、远程等等,每次都要不停的切换网站去查看,也经常漏掉一些不错的机会,还有一个就是有些是墙外的网站,有时候翻不过去就没办法查看。当然,还有一些其他想法,不过第一阶段主要就是解决这些问题。脑袋里就有了如下的想法: * 运行环境。因为是定时执行,而且还有墙外的网站,考虑到做出来的东西能让有需要的小伙伴一起用,脑袋灵光一闪,直接利用 Github Action 定时执行就好了,而且有需要的小伙伴直接 fork 一下,配置下相关环境变量就可以拥有自己的招聘信息推送机器人了。 * 开发语言选择。考虑后面扩展后, Github Action 的运行环境不大满足,那么能本地运行就挺好,所以希望产出是一个不需要环境依赖的可执行文件,能小点就小点,那就选 Go 吧。 * 抓取及处理策略。不同的网站数据格式不一样,需要根据网站添加解析策略,同时为了更有针对性过滤自己需要的信息,应该能够按照配置的 关键词 时间范围进行过滤。 * 推送。这里选了飞书,主要是使用飞书可配置 webhook 自定义机器人,消息格式也比较丰富些,其他的接收端也可以,
go Go指南-练习:Web 爬虫 的实现 Go 语言之旅Go 指南 练习:Web 爬虫 在这个练习中,我们将会使用 Go 的并发特性来并行化一个 Web 爬虫。 修改 Crawl 函数来并行地抓取 URL,并且保证不重复。 提示:你可以用一个 map 来缓存已经获取的 URL,但是要注意 map 本身并不是并发安全的! 实现: * 使用加锁的map类型保证并发安全-定义了: CrawlUrlMap * 使用 sync.WaitGroup 保证协程全部执行完后再退出主进程 package main import ( "fmt" "sync" ) type Fetcher interface { // Fetch 返回 URL 的 body 内容,并且将在这个页面上找到的 URL 放到一个 slice
go Golang 整理1-基本语法 go / Golang 编程语言学习 官方提供了教程,中文版的教程地址 可以边练习边学习 语法声明格式 https://blog.go-zh.org/gos-declaration-syntax 从左到右的规则 从左到右的写法与读法,符合读写习惯,尤其对于调用无名称的方法时尤为明显,如: func(a, b int) int { return a+b } (3, 4) 可以从左到右这样读出语义:一个函数,参数是 a 和 b ( int)类型的,返回值是: int 类型的,函数体是 {return a+b } ,执行该函数传入的参数是 3 和 4 数组类型 定义数组是 var a
关于GitHub Action fork pr自动化部署的问题 GitHub项目的fork pr 触发的Action 是无法获取到 secrets 的,这是GitHub出于安全考虑进行的限制,另外测试了GITHUB_TOKEN 的权限,设置 permissions 为 write-all (自动包含了读)仍然无法进行对库自动创建分支以及自动merge ,会报: Error: Resource not accessible by integration 的错误。 所以这里采用另外的一种方式实现:在fork pr 时触发自动化生成pr代码的 artifact ,然后再手动输入 fork pr number 的方式手动去触发一个流程,手动触发的流程是可以使用 secrets 的。 name: Upload fork pr files on: pull_request: branches: - '**' paths:
java java 单元测试工具的使用 作为后端开发的测试,个人认为主要关注两个维度:接口测试和单元测试,而接口测试,是否应该在后端项目的测试代码中实现,值得商榷,尤其对于当前的开发潮流,接口应该与具体的实现是无关的,接口测试应该面向接口规范,而前后端分离的模式,接口定义、接口模拟与接口测试的数据的生成规范应该是一致的,可考虑在此维度实现接口测试,相对于维护的问题,也不会带来太多麻烦,所以应该在项目代码层面更多的关注单元测试。这里就 java 语言生态中的单元测试工具进行使用说明。通过搜索引擎以及 Github 对比各个测试工具后,最后选择了 mockito * Github源码地址 * 官网地址 引入 官网有介绍如何引入,不过官网只说明了引入 mockito-core ,但是实际使用时还需要引入一些其他依赖,比如模拟静态类方法的实现等,常用的依赖包: * byte-buddy * byte-buddy-agent * objenesis * mockito-inline 可在 maven中央仓库 查找并根据自己的项目结构方式进行引入。需要注意的是包的发行方,别使用李鬼包。 使用示例 官网简单的
派安盈(payoneer)收款澳元攻略 第一步 注册派安盈 目前有活动,可以通过下方的链接,共同获取收益: Payoneer Refer a Friend ProgramNeed a simpler way to get paid from companies abroad? Get $25 when you sign up for Payoneer using my referral link!Payoneer 第二步 开通澳元账户 默认派安盈没有开通澳元账户,需要自己手动申请开启下,很快,入口在【收款】-【Global Payment Service】(注意:这个入口需要派安盈账号注册后,认证通过后才会出现-认证通过后要是没出现,可以试试退出重新刷新登入试试) 然后再跳转的页面里就可以看到申请入口了-按照提示进行操作就可以 第三步进行收款 入口:
使用fastjson反序列化对象 官方地址:https://github.com/alibaba/fastjson // 见 https://github.com/alibaba/fastjson/wiki/JSONType_seeAlso_cn @JSONType(seeAlso={Dog.class, Cat.class}) public static class Animal { } @JSONType(typeName = "dog") public static class Dog extends Animal { public String dogName; } @JSONType(typeName = "cat") public static class Cat extends Animal { public String catName;