定时抓取招聘信息推送到飞书机器人-v1.0.0

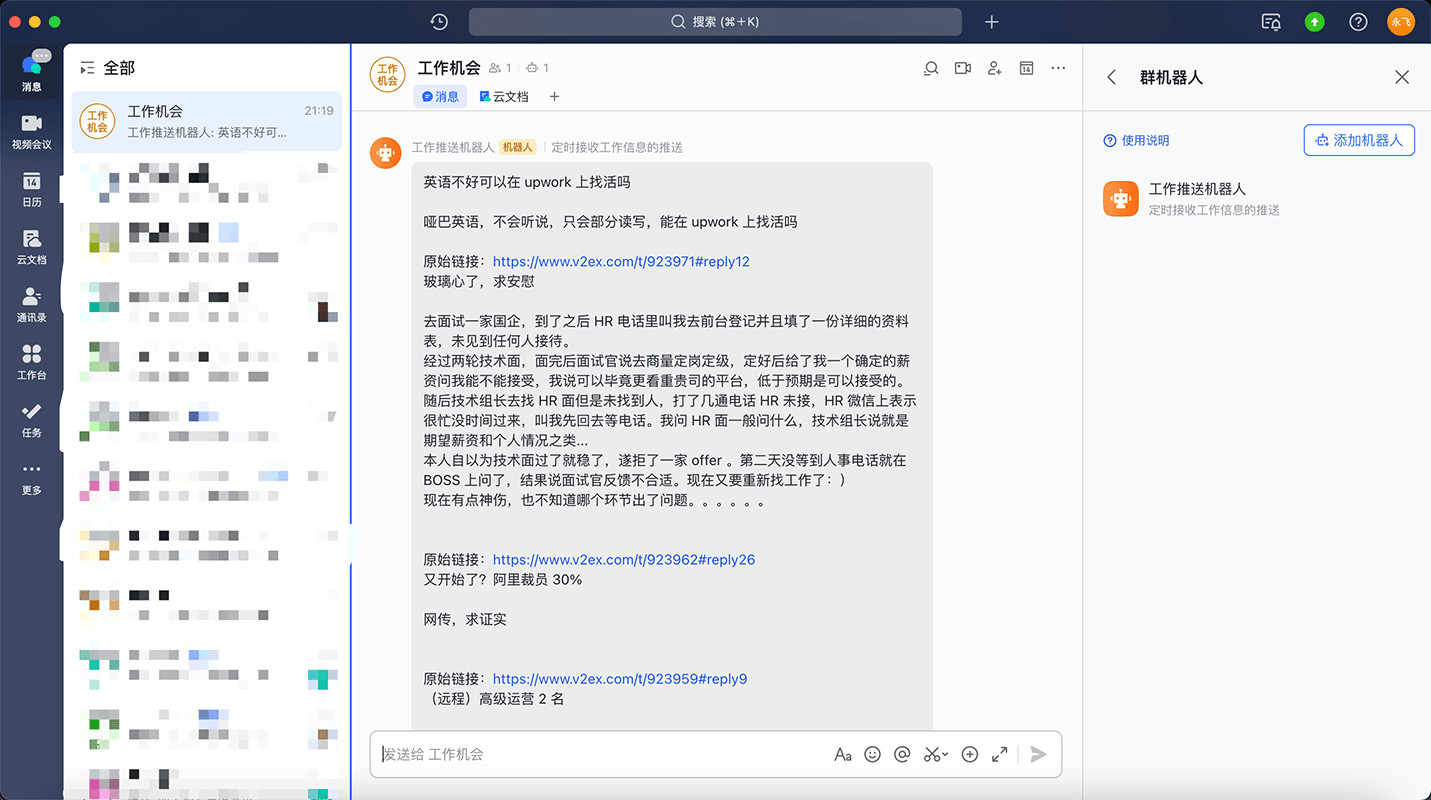
因为有不少网站论坛都提供一些招聘信息,包括兼职、全职、远程等等,每次都要不停的切换网站去查看,也经常漏掉一些不错的机会,还有一个就是有些是墙外的网站,有时候翻不过去就没办法查看。当然,还有一些其他想法,不过第一阶段主要就是解决这些问题。脑袋里就有了如下的想法:
- 运行环境。因为是定时执行,而且还有墙外的网站,考虑到做出来的东西能让有需要的小伙伴一起用,脑袋灵光一闪,直接利用
Github Action定时执行就好了,而且有需要的小伙伴直接fork一下,配置下相关环境变量就可以拥有自己的招聘信息推送机器人了。 - 开发语言选择。考虑后面扩展后,
Github Action的运行环境不大满足,那么能本地运行就挺好,所以希望产出是一个不需要环境依赖的可执行文件,能小点就小点,那就选Go吧。 - 抓取及处理策略。不同的网站数据格式不一样,需要根据网站添加解析策略,同时为了更有针对性过滤自己需要的信息,应该能够按照配置的
关键词时间范围进行过滤。 - 推送。这里选了飞书,主要是使用飞书可配置
webhook自定义机器人,消息格式也比较丰富些,其他的接收端也可以,暂时先选择飞书推送。另外Github Action本身就有很多已经写好的Action,当然也有推送飞书的Action,这块也省去了开发。【实现过程中考虑数据内容以及格式问题-且触发webhook并不麻烦-直接用代码实现推送反而更灵活】 - 数据。考虑后面版本能做更多的操作,所以希望定时抓取的数据能够存储起来,也适用
Github Action中生成文件,可以留档,数据格式中有原始链接,对于合适的需要登录才能投递或者查看联系方式的情况可以点击查看。【实现推送后发现推送批量数据并不是很合适,尤其是带着详细-很难抓住重点信息,且实时性也是一个考虑,改进的方向是爬取频率增加-以一条为消息的目标去推送】
综上,实际需要开发的内容就是: 使用 Go 开发一个爬取多个网站的数据,并能根据关键词及日期进行过滤。然后写 Github Action 脚本能够定时运行,并保存、推送过滤后的数据。
为了先看到效果,就先分为两个里程碑:
- 使用
Go开发一个爬取多个网站的招聘数据(暂时先支持一个网站),然后实现Github Action推送到飞书机器人。 - 对爬取数据进行关键字、日期范围过滤
Github 仓库
在 Github 上创建仓库: https://github.com/lyf-coder/job-opportunity-reminder
 lyf-coder
lyf-coder并添加对应的 project 信息及生成 issue 和创建相关里程碑。
实现
- 爬取
v2ex网站的酷工作
爬取 v2ex 网站的 酷工作 模块职位
- 确定模块的链接及查询、分页等参数
- 确定如何提取数据
- 实现
模块的链接及参数确定
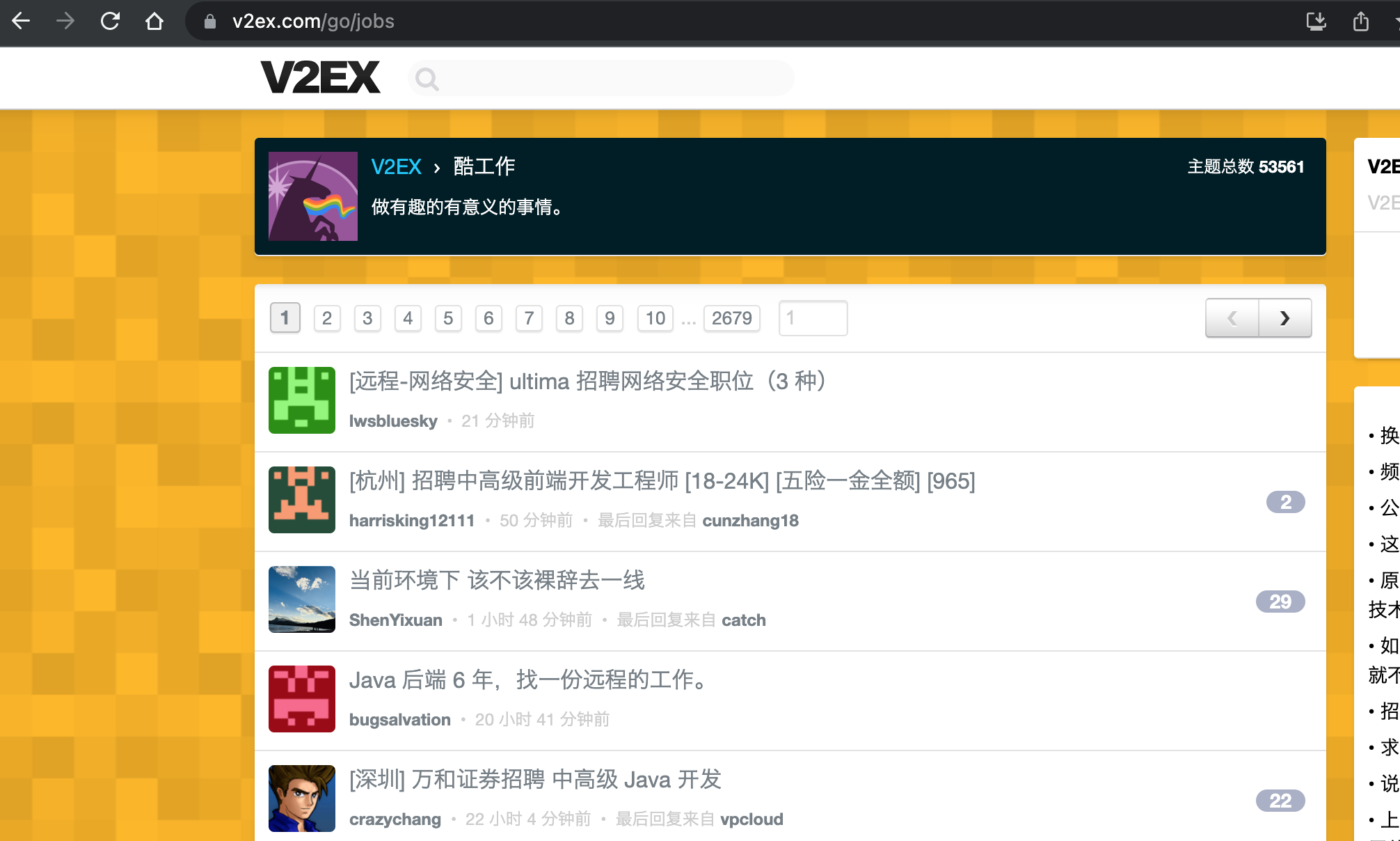
可以看到模块的数据是分页的,点击分页观察链接变化
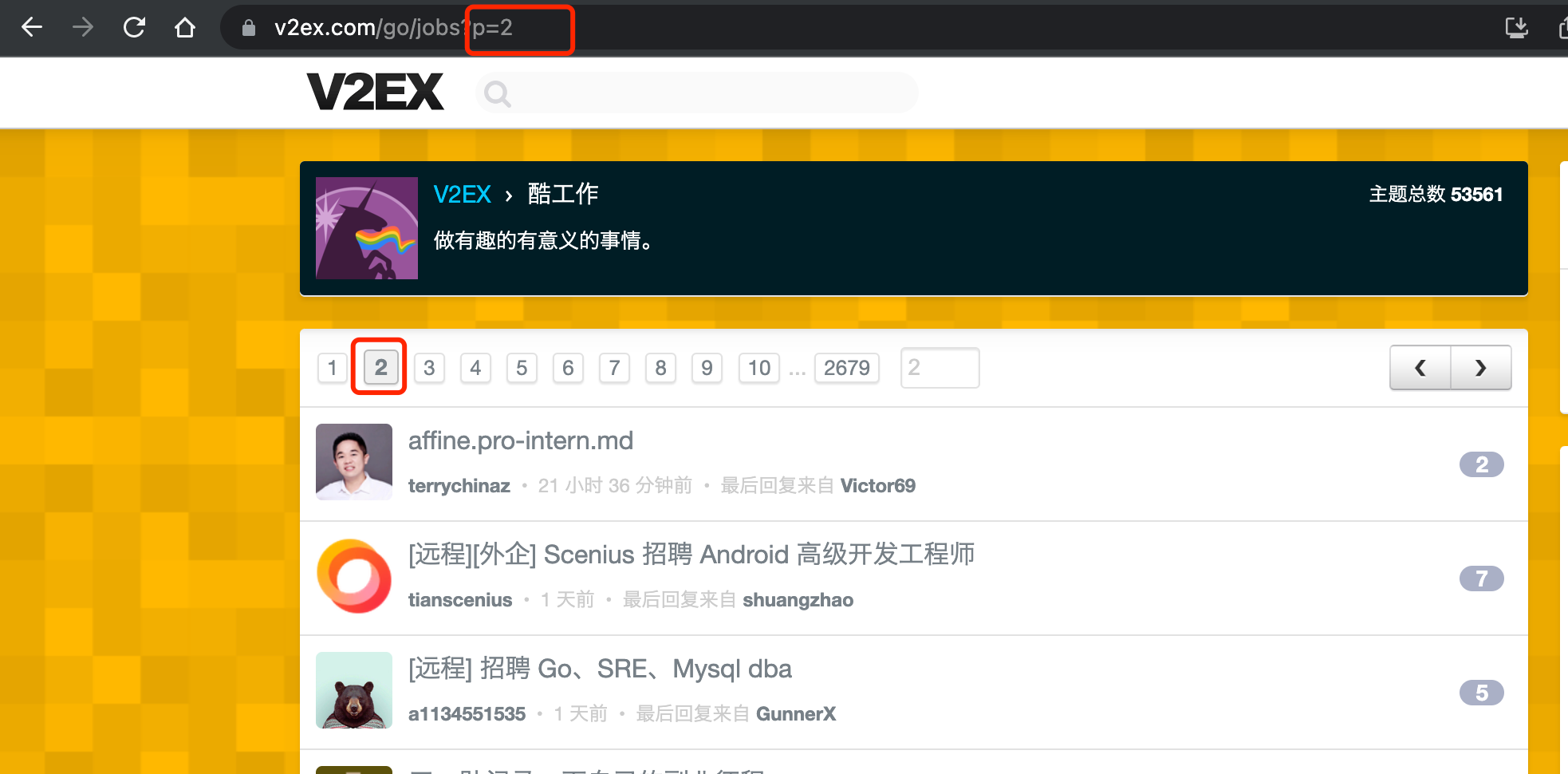
多测试几个翻页可以看到链接的参数 p 就是分页序号。页面没有看到其它可设置的过滤条件。所以有如下结论:
- 爬取页面链接为:
https://www.v2ex.com/go/jobs - 链接参数:
p切换页码
数据提取
通过打开浏览器的控制台,观察切换页码时加载的资源列表,确定没有直接的数据接口,而是招聘数据在页面中,需要处理提取。
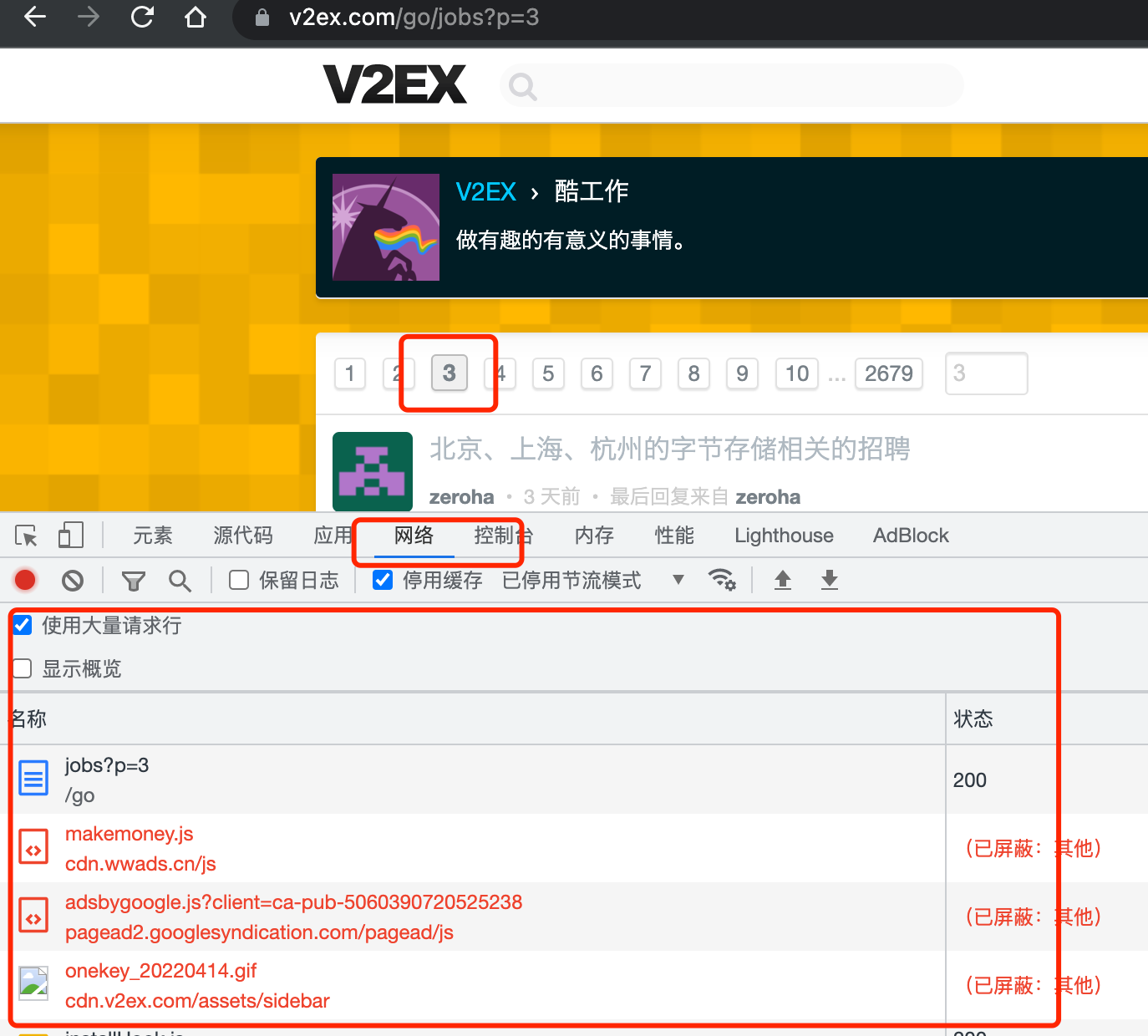
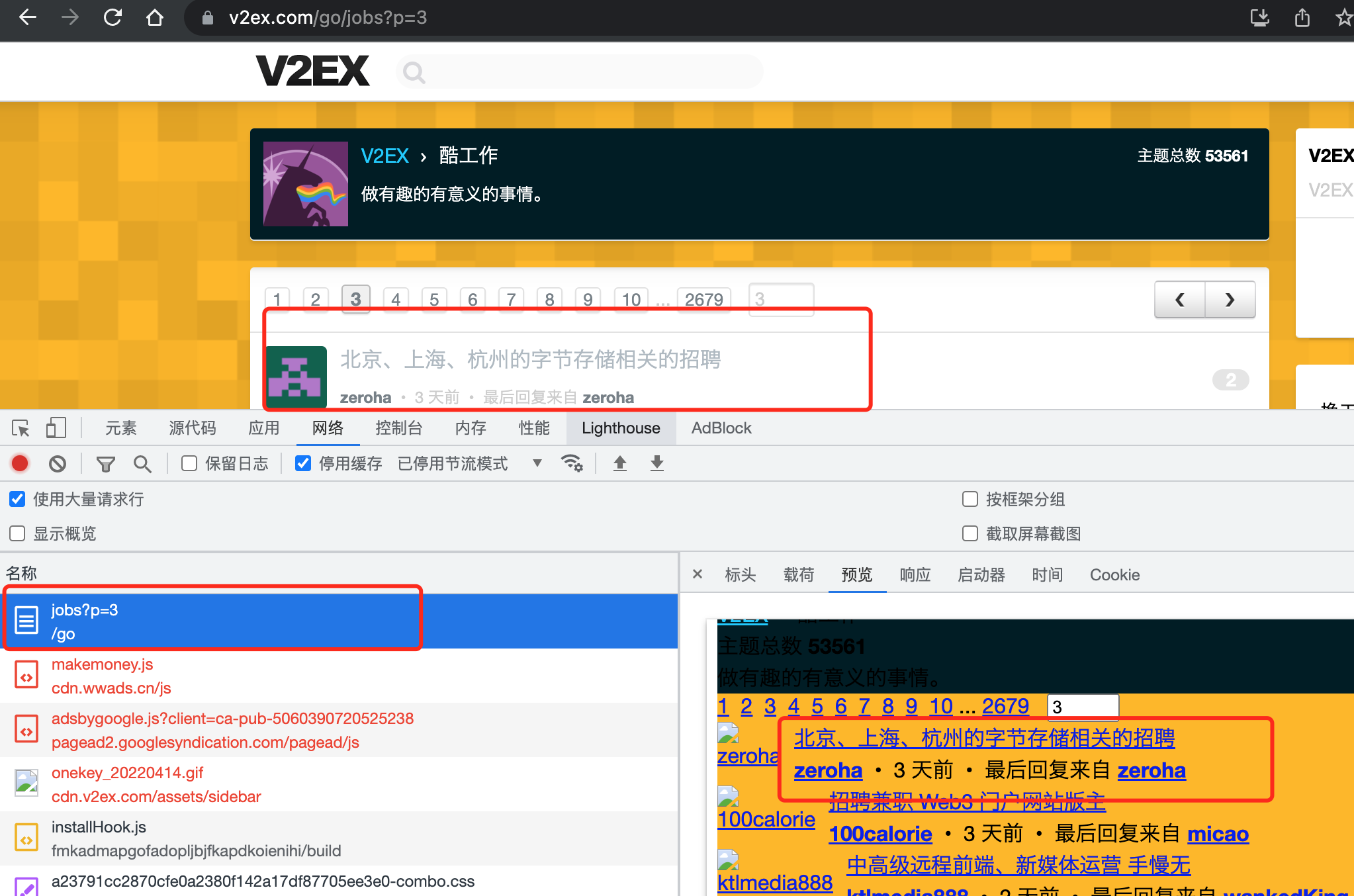
然后观察每条数据的内容,确定我们要提取每条数据的内容:
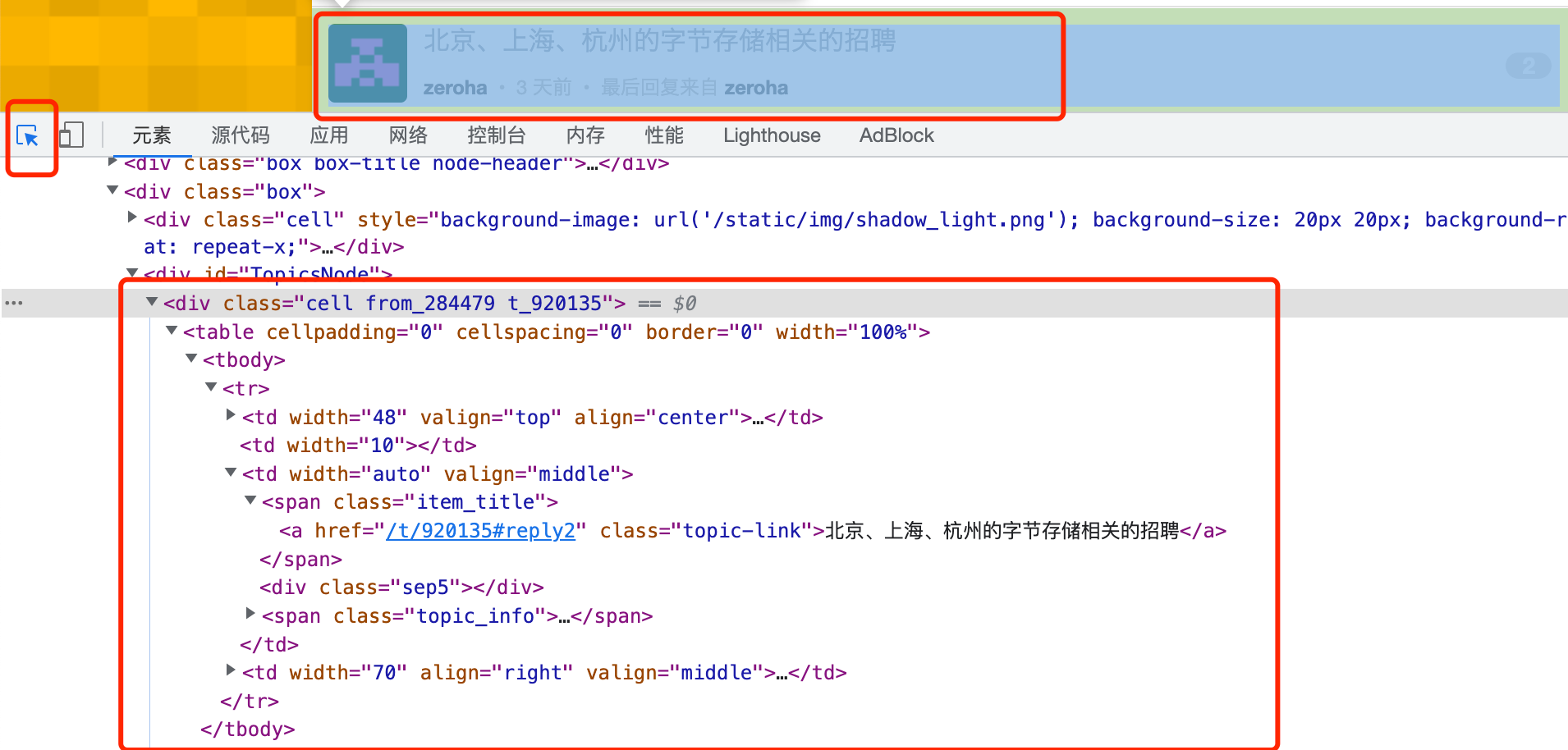
可以看到每条数据单元对应的区块时一个 div 包含的 table ,再次确认下,折叠该 div 查看:
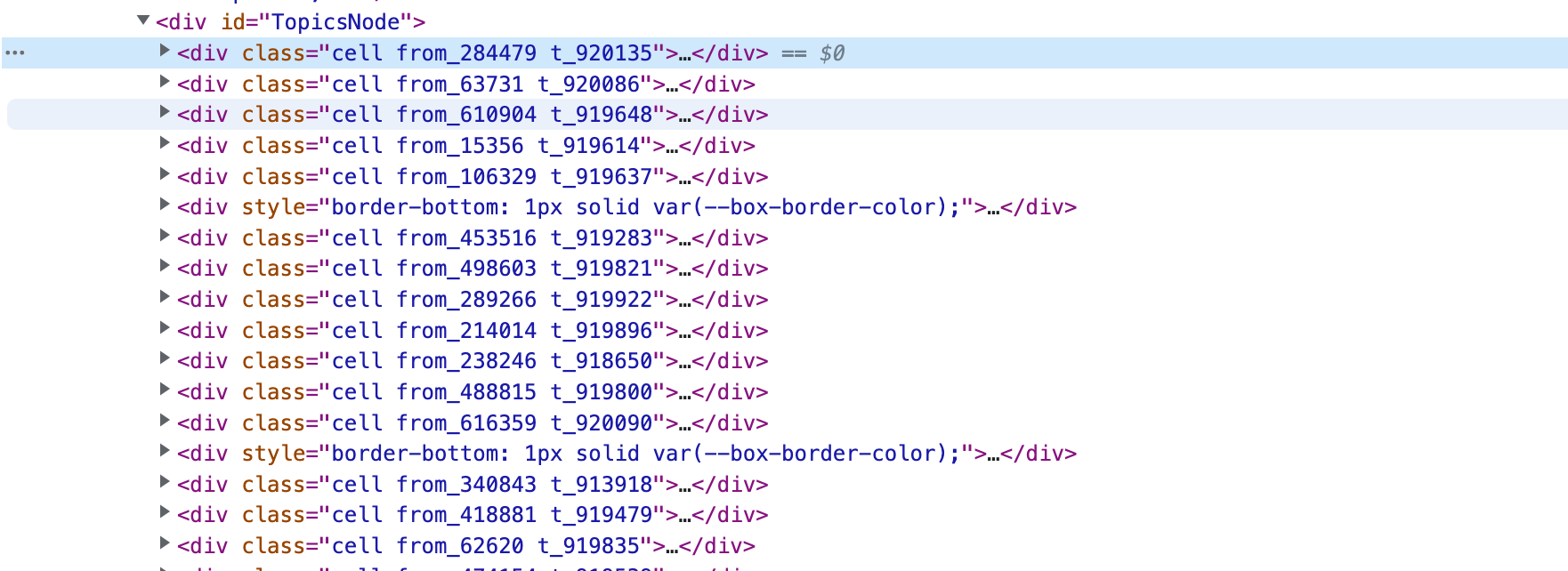
基本可以确认,只需要查找 id="TopicsNode" 下的 Table 就可以了(没用 div 是直接跳过广告条目)。
而每个数据里面包含几个部分:
- 头像
- 招聘标题 及 详细链接
- 发布人 及 个人主页链接
- 最后回复人及回复人主页链接、最后回复时间
- 回复数量
展示的列表里面是没有发布时间的,但是从观察的一些帖子详细页面里的时间看,默认的查询结果是按照发布时间是倒叙排列的,即最新的帖子在最前面。
考虑实际需要,我们暂时只需要 招聘标题 详细链接 最后回复时间 回复数量 其它的暂时先不关注及处理。( 最后回复时间及 回复数量的保留主要是相对能代表帖子的火热程度)然后通过审查工具查看具体的标签信息,可以分别获取到对应数据提取的路径。
所以有如下结论:
- 获取页面元素ID(
TopicsNode)下所有的Table元素列表 - 遍历每个
table元素,然后提取里面的数据 :招聘标题及详细链接通过a标签class为topic-link获取;最后回复时间通过有title属性的span标签获取;回复数量通过class为count_livid的a标签获取,假如不存在则说明回复数量为0
详细链接的处理
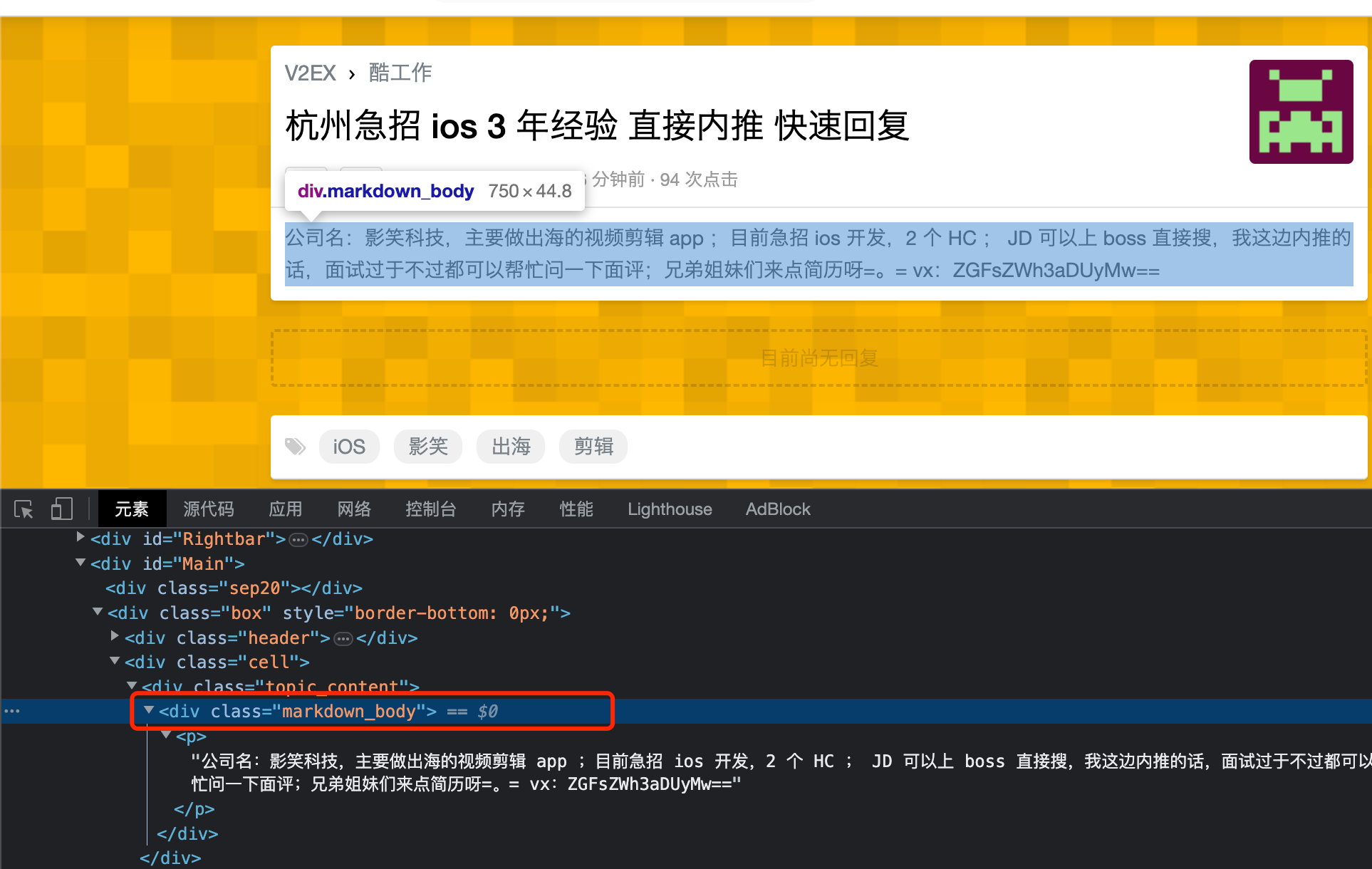
考虑仅有标题很难确定招聘的职位,而且详情链接还是需要翻墙才能打开,所以还是需要去获取每条记录的详情内容。
这里先打开了几个招聘条目的链接,审查详情页面发现详情内容主要在 class 为 topic_content ( markdown_body 并非所有都有) 的标签内,且是一个富文本格式。例如:
实现
- 使用
github.com/gocolly/colly/v2包进行爬虫处理。 - 按照上方的思路进行的抓取实现:
- 实现时考虑多个详细页面需要分别去爬取,一页20条目,也就是爬20个详情页面,所以此处采用并发提高执行速度,另外并发之间做了一定的延迟-防止高并发导致被网站禁止访问。
- 推送实现
- 飞书机器人的推送实现
package crawler
import (
"fmt"
"github.com/gocolly/colly/v2"
"strconv"
"sync"
"time"
)
// V2exCrawler v2ex 爬虫
var V2exCrawler = &v2exCrawler{
// 默认配置-查询 2 个页面
PagesNum: 2,
}
// 爬取的url地址
const v2exUrl = "https://www.v2ex.com"
const jobUrl = v2exUrl + "/go/jobs?p="
// V2exItem v2ex 网站的返回的条目数据结构
type V2exItem struct {
Item
// 最后回复时间
LastReplyTime string `json:"lastReplyTime,omitempty"`
// 回复数量
ReplyCount int `json:"replyCount,omitempty"`
}
// v2exCrawler v2ex 爬虫
type v2exCrawler struct {
// 查询页数
PagesNum int
// 代理地址 可选 示例:"socks5://127.0.0.1:3128"
ProxyUrl string
}
// 爬取详情页面,相关处理数据存储到 v2exItem 中
func (v2exItem *V2exItem) crawlDetailPage(proxyUrl string) {
c := colly.NewCollector()
// 处理页面-class 为 topic_content
c.OnHTML(`div.topic_content`, func(e *colly.HTMLElement) {
v2exItem.Content = e.Text
})
// 设置代理
if len(proxyUrl) > 0 {
err := c.SetProxy(proxyUrl)
if err != nil {
fmt.Println("设置代理地址失败!", proxyUrl, err)
}
}
err := c.Visit(v2exItem.Url)
if err != nil {
fmt.Println("访问详细页面失败!", v2exItem.Url, err)
}
}
// crawlPage 爬取具体的页面
func crawlPage(pageNum int, proxyUrl string) ([]interface{}, error) {
// 保证多个协程完成执行
var wg = sync.WaitGroup{}
var list []interface{}
c := colly.NewCollector()
// id 为 TopicsNode 的 div
c.OnHTML(`div[id=TopicsNode]`, func(e *colly.HTMLElement) {
// 找到 table 元素列表遍历
e.ForEach(`table`, func(i int, eTable *colly.HTMLElement) {
count := 0
countStr := eTable.ChildText(`a.count_livid`)
if len(countStr) > 0 {
var err error
count, err = strconv.Atoi(countStr)
if err != nil {
fmt.Println("转换回复数量时出错", err)
}
}
v2exItem := &V2exItem{
Item: Item{
Title: eTable.ChildText(`a.topic-link`),
Url: v2exUrl + eTable.ChildAttr(`a.topic-link`, "href"),
},
LastReplyTime: eTable.ChildAttr(`span`, "title"),
ReplyCount: count,
}
list = append(list, v2exItem)
wg.Add(1)
go func() {
v2exItem.crawlDetailPage(proxyUrl)
wg.Done()
}()
// 防止同一时间的高并发请求导致被禁止访问
time.Sleep(200 * time.Millisecond)
})
})
// 设置代理
if len(proxyUrl) > 0 {
err := c.SetProxy(proxyUrl)
if err != nil {
return nil, err
}
}
err := c.Visit(jobUrl + strconv.Itoa(pageNum))
// 等待详情信息抓取处理完成
wg.Wait()
return list, err
}
func (crawler *v2exCrawler) Crawl() []interface{} {
var list []interface{}
for i := 1; i <= crawler.PagesNum; i++ {
pageDataList, err := crawlPage(i, crawler.ProxyUrl)
if err != nil {
fmt.Println("爬取页面失败", i, err)
continue
}
list = append(list, pageDataList...)
}
return list
}
package receiver
import (
"bytes"
"encoding/json"
"io"
"io/ioutil"
"log"
"net/http"
)
// Receiver 接收者
type Receiver interface {
Receive() error
}
const JsonContentType = "application/json;charset=utf-8"
// Post 发起Post请求
func Post(url string, body interface{}) ([]byte, error) {
jsonByte, err := json.Marshal(body)
if err != nil {
log.Println("转换json错误!")
return nil, err
}
resp, err := http.Post(url, JsonContentType, bytes.NewReader(jsonByte))
if err != nil {
log.Println("http请求失败!")
return nil, err
}
defer func(Body io.ReadCloser) {
err := Body.Close()
if err != nil {
log.Println(err, "关闭请求响应body时出现错误!")
}
}(resp.Body)
return ioutil.ReadAll(resp.Body)
}
package receiver
import (
"encoding/json"
"errors"
"github.com/lyf-coder/job-opportunity-reminder/crawler"
"log"
"strings"
)
// FeiShuReceiver 飞书webhook作为接受者
type FeiShuReceiver struct {
Url string
Data []interface{}
}
func (r *FeiShuReceiver) Receive() error {
var contentArr []string
for _, itemData := range r.Data {
item, ok := itemData.(*crawler.V2exItem)
if ok {
contentArr = append(
contentArr, item.Title, "\n\n",
item.Content, "\n\n",
"原始链接:", item.Url, "\n")
}
}
respData, err := Post(r.Url, &textMsgBody{
MsgType: text,
Content: struct {
Text string `json:"text"`
}{
Text: strings.Join(contentArr, ""),
},
})
if err != nil {
log.Println(`发送飞书消息失败!`)
return err
}
var resp respBody
err = json.Unmarshal(respData, &resp)
if err != nil {
log.Println(`转换飞书响应值失败!`, string(respData))
}
if resp.Code != 0 {
log.Println(`飞书响应错误编码!`, string(respData))
return errors.New(resp.Msg)
}
return nil
}
// MsgType 飞书消息类型
// 参考 https://open.feishu.cn/document/uAjLw4CM/ukTMukTMukTM/im-v1/message/events/message_content#c9e08671
// https://open.feishu.cn/document/ukTMukTMukTM/ucTM5YjL3ETO24yNxkjN
// https://open.feishu.cn/document/uAjLw4CM/ukTMukTMukTM/im-v1/message/create_json#45e0953e
type MsgType string
const (
// text 文本消息类型
text MsgType = "text"
// post 富文本
post MsgType = "post"
// 消息卡片
interactive MsgType = "interactive"
)
// 文本消息结构
type textMsgBody struct {
MsgType MsgType `json:"msg_type"`
Content struct {
Text string `json:"text"`
} `json:"content"`
}
// 发送给飞书的请求响应体
type respBody struct {
// 0 为成功
Code int `json:"code"`
Msg string `json:"msg"`
Data struct {
} `json:"data"`
}
实现的更多内容参见:
lyf-coder