定时抓取招聘信息推送到飞书机器人-v1.2.0-支持电鸭社区

GitHub - lyf-coder/job-opportunity-reminder: 爬取招聘网站上的招聘信息,然后推送到飞书等通讯工具
爬取招聘网站上的招聘信息,然后推送到飞书等通讯工具. Contribute to lyf-coder/job-opportunity-reminder development by creating an account on GitHub.
 lyf-coder
lyf-coder在 v1.1.0 版本上开发,支持抓取 电鸭社区-招聘 数据推送到飞书机器人
- 抓取数据地址: https://eleduck.com/categories/5?sort=new
- 通过观察网络请求,发现数据也是后端渲染到页面中,所以需要从页面中提取,比较有趣的是在观察页面的过程中,发现页面上是存在结构化的
json格式的数据,如图所示:
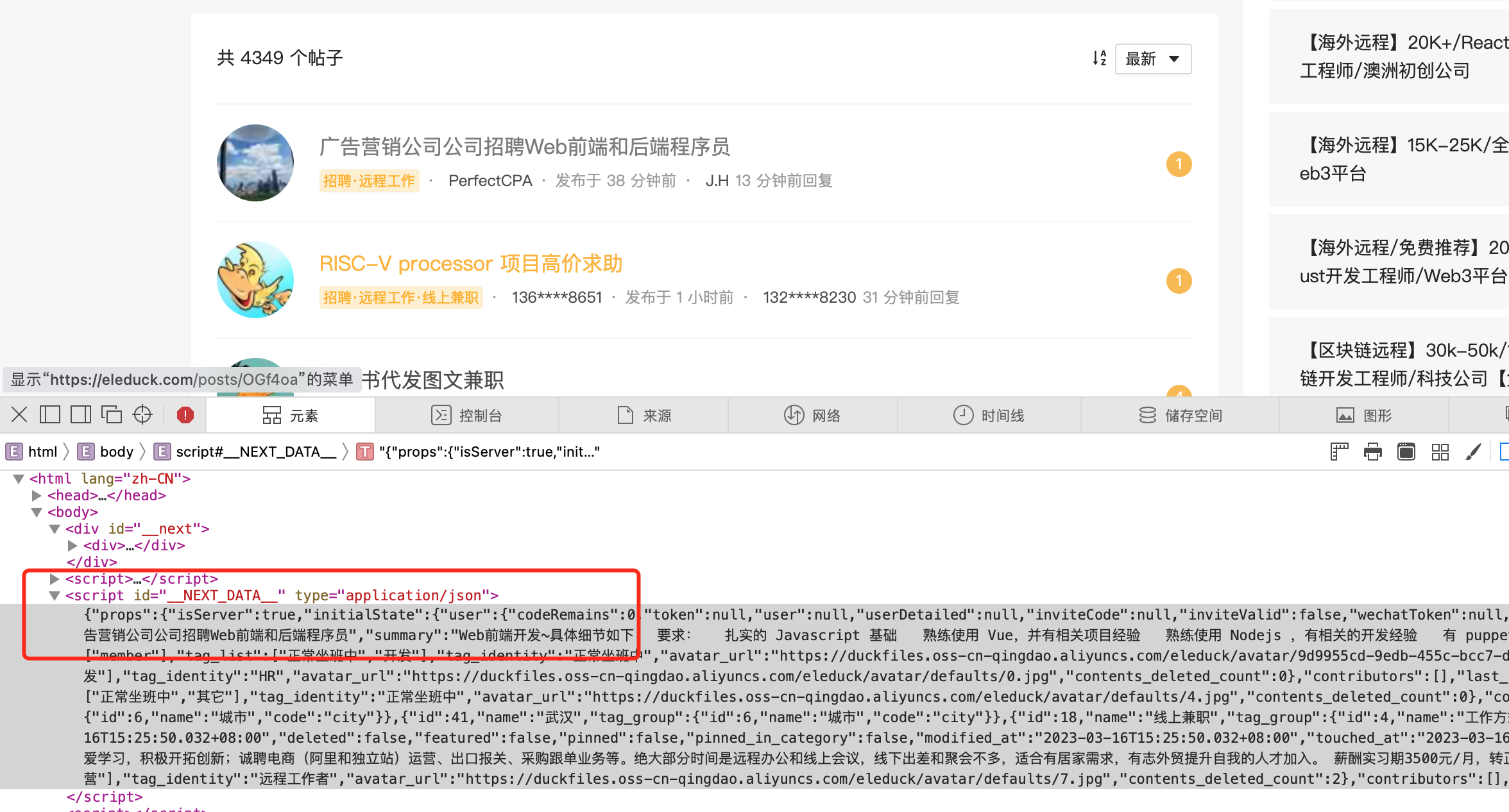
通过 script 标签的 id=__NEXT_DATA__ 可以获取该数据。数据中包含招聘数据列表信息。观察招聘数据条目信息发现详细内容不全,所以仍然要进一步访问详细页面,通过点击条目的链接发现请求了接口 https://svc.eleduck.com/api/v1/posts/OGf4oa 最后的 OGf4oa 是数据条目的id字段,数据格式如下(去掉了一些不关注的数据):
{
"post": {
"id": "OGf4oa",
"title": "RISC-V processor 项目高价求助",
"published_at": "2023-03-16T17:53:47.221+08:00",
"modified_at": "2023-03-16T18:32:46.389+08:00",
"featured": false,
"pinned": false,
"pinned_in_category": false,
"views_count": 28,
"comments_count": 1,
"touched_at": "2023-03-16T18:32:46.389+08:00",
"charges_count": 0,
"charges_ele": 0,
"raw_content": "Implement cycle-accurate simulators of a 32-bit RISC-V processor in C++ or Python\n\n 此项目为课程project,确认有能力完成再联系我们看具体需求,谢谢",
"hide": false,
"hided_at": null,
"upvotes_count": 0,
"downvotes_count": 0,
"marks_count": 1,
"deleted": false,
"content": "\u003cp\u003eImplement cycle-accurate simulators of a 32-bit RISC-V processor in C++ or Python\u003c/p\u003e\n\u003cp\u003e此项目为课程project,确认有能力完成再联系我们看具体需求,谢谢\u003c/p\u003e\n"
}
}按照 Crawler 接口规范,参考 V2exCrawler 实现 EleDuckCrawler ,在实现过程中,因为都要过滤数据,且对于 v2ex 的数据需要抓取详细页面以后才能得到发布时间进行过滤而言, eleDuck 在列表页面就可以获取到发布时间进行过滤,这样可以减少对不必要的详细页面的访问。因此重构提取了实现,见 crawler struct
- 引入配置文件。考虑方便修改配置文件以及本地运行,引入
viper,然后选择使用yaml格式配置文件,方便添加配置说明的注释。(同时在加载配置中选择环境变量优先,假如配置了对应的环境变量,则覆盖配置文件中的配置,同时配置环境变量需要全大写)
# 配置对应的环境变量应该大写,否则不能生效覆盖配置文件内的配置 如 PROXY_URL
# 代理url
proxy_url: ''
# 过滤的时间范围-单位秒-配置此值代表只发送在当前时间内此时间段的新发布数据,比如 300 代表5分钟内的数据
duration_sec: 300
# 飞书机器人 webhook 地址
fei_shu_bot_webhook_url: ''
- 优化了消息的结构,新增了来源项,方便区分消息来源。
具体实现:
GitHub - lyf-coder/job-opportunity-reminder at v1.2.0
爬取招聘网站上的招聘信息,然后推送到飞书等通讯工具. Contribute to lyf-coder/job-opportunity-reminder development by creating an account on GitHub.
lyf-coder